更新时间:2022-12-21 来源:黑马程序员 浏览量:

停用词是指在信息检索中,为节省存储空间和提高搜索效率,在处理自然语言文本之前或之后会自动过滤掉某些没有具体意义的字或词,这些字或词即被称为停用词,比如英文单词“I”“the”或中文中的“啊”等。
停用词的存在直接增加了文本的特征难度,提高了文本数据分析过程中的成本,如果直接用包含大量停用词的文本作为分析对象,则还有可能会导致数据分析的结果存在较大偏差,通常在处理过程中将它们从文本中删除,如图8-4所示。
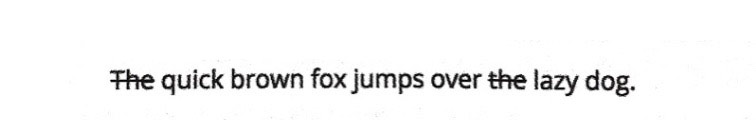
图8-4 删除停用词示例
从图8-4中可以看出,即使从整个语句中删除了停用词,句子整体的意思并没有产生很大的影响。
停用词都是人工输入、非自动化生成的,生成后的停用词会形成一个停用词表,但是并没有一个明确的停用词表能够适用于所有的工具。对于中文的停用词,可以参考中文停用词库、哈工大停用词表、百度停用词列表,对于其他语言来说,可以参照https://www.ranks.nl/stopwords进行了解。
删除停用词常用的方法有词表匹配法、词频阈值法和权重阈值法,NLTK库所采用的就是词表匹配法,它里面有一个标准的停用词列表,在使用之前要确保已经下载了stopwords语料库,并且用import语句导入stopwords模块,示例代码如下。
In [20]: from nltk.corpus import stopwords
# 原始文本
sentence='Python is a structured and powerful object-oriented
programming language.'
# 将英文语句按空格划分为多个单词
words=nltk.word_tokenize(sentence)
words
Out[20]: ['Python', 'is', 'a', 'structured', 'and', 'powerful', 'object-oriented', 'programming', 'language', '.']
In [22]: # 获取英文停用词列表
stop_words=stopwords.words('english')
# 定义一个空列表
remain_words=[]
# 如果发现单词不包含在停用词列表中,就保存在remain_words中
for word in words:
if word not in stop_words:
remain_words.append(word)
remain_words
Out[22]: ['Python', 'structured', 'powerful', 'object-oriented',
'programming', 'language', '.']通过比较删除前与删除后的结果可以发现,is、a、and这几个常见的停用词都被删除了。
AI鸿蒙原生智能正式版课程,培养全端跨平台鸿蒙工程师
2026-03-10AI鸿蒙原生智能正式版课程,培养全端跨平台鸿蒙工程师
2026-03-10毕业16个工作日,平均薪资13180元,就业率100%,广州黑马AI智能应用开发(Java)学科20250529班
2026-03-06毕业32个工作日,平均薪资11147元,就业率95%,广州黑马AI智能应用开发(Java)学科20250326班
2026-03-05黑马程序员2025全国就业数据发布:全学科平均就业率92.07%,AI开发类就业平均薪资达11869.67元。
2026-03-05黑马全国校区齐开班!场面太太太壮观了!
2026-03-03
















 AI智能应用开发
AI智能应用开发 AI大模型开发
AI大模型开发 AI鸿蒙开发
AI鸿蒙开发 AI嵌入式+
AI嵌入式+ AI大数据开发
AI大数据开发 AI运维
AI运维 AI测试
AI测试 跨境电商运营
跨境电商运营 AI设计
AI设计 AI视频创作运营
AI视频创作运营

















.jpg)